一、DLCN [2013]
《Spectral Networks and Deep Locally Connected Networks on Graphs》
卷积神经网络(
Convolutional Neural Networks: CNNs)在机器学习问题中非常成功,其中底层数据representation的坐标具有网格结构(grid structure)(一维、二维、或三维的网格),并且在这些坐标中,这些待研究的数据相对于该网格具有平移相等性(translational equivariance)或平移不变性 (translational invariance)。语音、图像、视频就是属于这一类问题的著名的例子。在常规网格上,
CNN能够利用多种结构来很好地协同工作,从而大大减少系统中的参数数量:平移结构 (
translation structure):它允许使用filter而不是通用的线性映射,从而实现权重共享(weight sharing)。空间局部性:
filter的尺寸通常都远远小于输入信号的尺寸。多尺度:通过步长大于一的卷积或者池化操作来减少参数,并获得更大的感受野(
receptive field) 。
然而在许多情况下,数据并不是网格结构,如社交网络数据,因此无法在其上应用标准的卷积网络。图 (
graph)提供了一个自然框架来泛化网格结构,并扩展了卷积的概念。在论文《Spectral Networks and Deep Locally Connected Networks on Graphs》中,作者将讨论在除了常规网格之外的图上构建深度神经网络。论文提出了两种不同的结构:基于空域的卷积构建 (
Spatial Construction):通过将空间局部性和多尺度扩展到通用的图结构,并使用它们来定义局部连接和池化层,从而直接在原始图结构上执行卷积。基于谱域的卷积构建(
Spectral Construction):对图结构进行傅里叶变换之后,在谱域进行卷积。
论文主要贡献如下:
论文表明,从给定的图结构输入,可以获得参数为
论文介绍了一种使用
harmonic analysis problem) 的联系。
1.1 基础概念(读者补充)
1.1.1 拉普拉斯算子
散度定义:给定向量场
当
其中
散度的物理意义为:在向量场中从周围汇聚到该点或者从该点流出的流量。
旋度定义:给定向量场
当
在三维空间中,上式等于:
旋度的物理意义为:向量场对于某点附近的微元造成的旋转程度,其中:
旋转的方向表示旋转轴,它与旋转方向满足右手定则。
旋转的大小是环量与环面积之比。
拉普拉斯算子定义:给定函数
梯度的物理意义为:函数值增长最快的方向。
梯度的散度为拉普拉斯算子,记作:
由于所有的梯度都朝着
拉普拉斯算子也能够衡量函数的平滑度
smoothness:函数值没有变化或者线性变化时,二阶导数为零;当函数值突变时,二阶导数非零。
图拉普拉斯矩阵:假设
二阶导数为二阶差分:
一维函数其自由度可以理解为
2,分别是+1和-1两个方向。因此二阶导数等于函数在所有自由度上微扰之后获得的增益。推广到图结构
令
函数
signal。对于节点
其中:
degree matrix,考虑所有的节点,则有:
定义拉普拉斯矩阵
上述结果都是基于
假设图的节点数量为
对称矩阵一定有
半正定矩阵的特征值一定是非负的。
对称矩阵的特征向量相互正交,即:所有特征向量构成的矩阵为正交矩阵。
因此有拉普拉斯矩阵的谱分解:
其中
解得:
根据
根据特征方程:
在
PCA降维也是同样原理,把协方差矩阵特征分解后,取top K个特征值对应的特征向量作为新的特征空间。 如下图所示为包含25个节点的图,其25维空间中,最大特征值、第12大特征值、次小特征值(因为最小特征值为零,因此第24大特征值就是次小的)对应特征向量1的向量(或者乘以常数倍),这意味着该特征向量在所有节点上取值相等(所以变化为零),即频率为零的分量。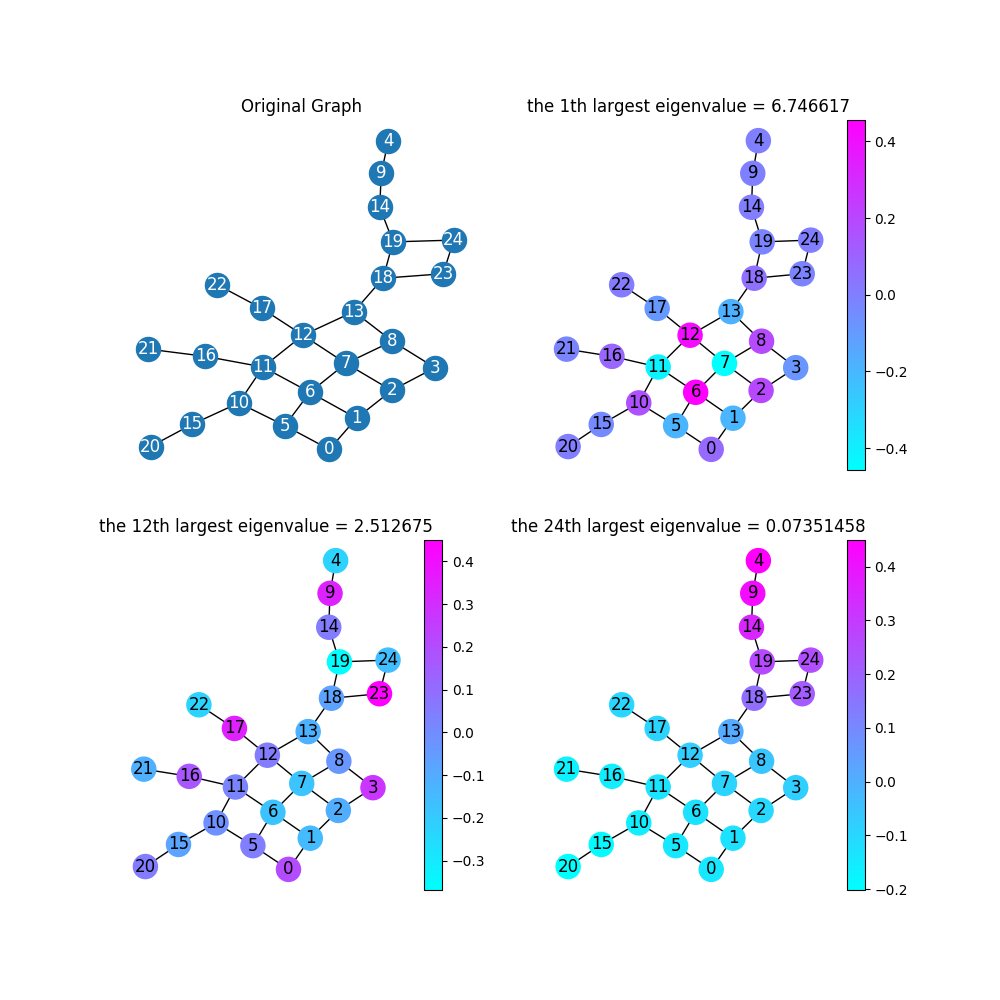
1.1.2 卷积
给定函数
其中
fouries basis。可以证明:
如果将傅里叶变换推广到图上,则有类比:
拉普拉斯算子对应于拉普拉斯矩阵
频率
傅里叶基
傅里叶系数
写成矩阵形式为:
其中:
传统的傅里叶逆变换
其中
卷积定理:两个函数在时域的卷积等价于在频域的相乘。
对应于图上有:
其中:
这里将逐元素乘积转换为矩阵乘法。
图卷积神经网络的核心就是设计卷积核,从上式可知卷积核就是
我们并不关心
1.2 空域构建 Spatial Construction
1.2.1 基本概念
在通用的图结构上针对
CNN最直接的推广是考虑多尺度的、局部的感受野。为此,我们使用一个加权图这里的权重指的是图中边的权重,而不是神经网络的权重。
基于
locality):可以很容易地在图结构中推广局部性的概念。实际上,图中的权重决定了局部性的概念。例如,在其中
在执行卷积时,我们可以仅仅考虑将感受野限制在这些邻域上的
sparse filter,从而获得局部连接的网络(locally connected network),从而将卷积层的参数数量减少到每个节点需要
图的多分辨率(
multiresolution)分析:CNN通过池化(pooling) 层和降采样(subsampling)层来减少feature map的尺寸,在图结构上我们同样可以使用多尺度聚类(multiscale clustering)的方式来获得多尺度结构。在图结构上如何进行多尺度聚类仍然是个开发的研究领域,我们这里根据节点的邻域进行简单的聚类。图的邻域结构天然地代表了某种意义上的聚类。比如,社交网络的一阶邻域代表用户的直接好友圈子,以一阶邻域来聚类则代表了一个个的”小团体“。基于这些 ”小团体“ 进行聚类得到的高阶聚类可能包含了国家的信息,比如”中国人“被聚合在一个高阶聚类中,”美国人“被聚合在另一个高阶聚类中。
下图给出了多尺度层次聚类的示意图(两层聚类)。原始的
12个节点为灰色。第一层有6个聚类,聚类中心为彩色节点,聚类以彩色块给出。第二层有3个聚类,聚类以彩色椭圆给出。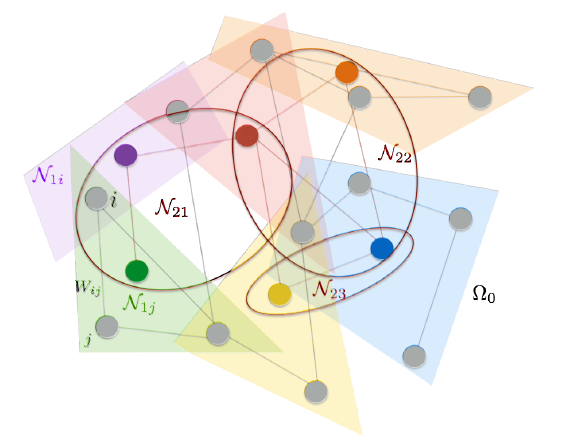
1.2.2 深度局部连接网络 Deep Locally Connected Networks
空域构建(
spatial construction)从图的多尺度聚类开始,并且我们考虑scale)。定义第0个尺度表示原始图,即feature map,feature map有了这些之后我们现在可以定义神经网络的第
real signal)(即标量值) ,我们设第filter数量为正式地,假设第
其中:
feature map。feature。
则第
其中:
信号的每一维度表示一个通道,因此
sum聚合而来。filter),它表示应用于第即:当节点
filter的待学习的参数。这意味着在线性投影时,节点
cluster id,列表示节点id,矩阵中的元素表示每个节点对应于聚类中心的权重:如果是均值池化则就是1除以聚类中的节点数,如果是最大池化则是每个聚类的最大值所在的节点。
初始化:
根据对
对于
然后按行进行归一化:
根据
如下图所示
12个节点(灰色),信号为一个通道(标量)。6个节点,输出信号四个通道(四个filter)。3个节点,输出信号六个通道(六个filter)。
每一层卷积都降低了空间分辨率
spatial resolution,但是增加了空间通道数。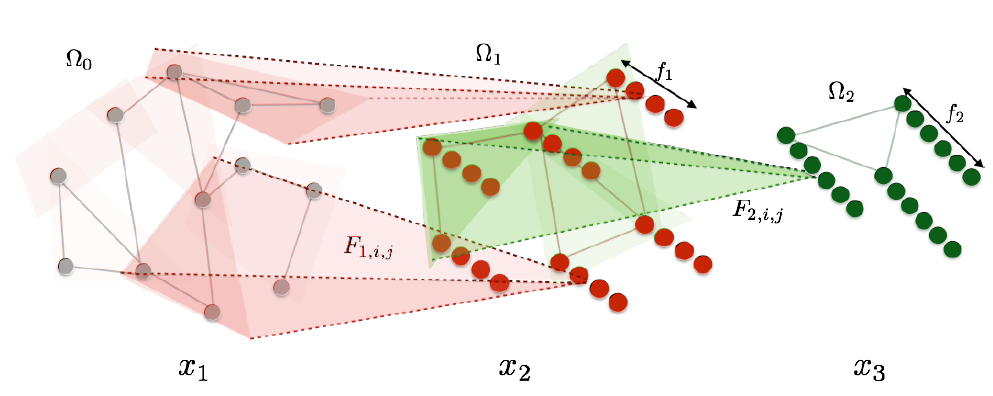
假设
实际应用中我们可以使得
为什么这么做?论文并未说明原因。
空域构建的实现非常朴素,其优点是不需要对图结构有很高的规整性假设 (
regularity assumption)。缺点是无法在节点之间实现权重共享。
1.3 谱域构建 Spectral Construction
可以通过图拉普拉斯算子来探索图的全局结构,从而推广卷积算子。
假设构建一个
feature map其中:
实际应用中,通常仅仅使用拉普拉斯矩阵的最大
regularity以及图的节点数量。此时上式中的filter。一般而言我们选择filter我们将在后文看到如何将图的全局规整性和局部规整性结合起来,从而产生具有
谱域构建可能受到以下事实的影响:大多数图仅在频谱的
top(即高频部分)才具有有意义的特征向量。即使单个高频特征向量没有意义,一组高频特征向量也可能包含有意义的信息。然而,我们的构建方法可能无法访问这些有意义的信息,因为我们使用对角线形式的卷积核,在最高频率处它是对角线形式因此仅包含单个高频特征向量(而不是一组高频特征向量)。
傅里叶变换是线性变换,如何引入非线性目前还没有很好的办法。
具体而言,当在空域执行非线性变换时,如何对应地在谱域执行前向传播和反向传播,目前还没有很好的办法,因此我们必须进行昂贵的
为了降低参数规模,一个简单朴素的方法是选择一个一维的排列(
arrangement)(这个排列的顺序是根据拉普拉斯特征值的排序得到)。此时第filter其中:
假设采样步长正比于节点数量,即步长
1.4 实验
我们对
MNIST数据集进行实验,其中MNIST有两个变种。所有实验均使用ReLU激活函数以及最大池化。模型的损失函数为交叉熵,固定学习率为0.1,动量为0.9。
1.4.1 降采样 MNIST
我们将
MNIST原始的28x28的网格数据降采样到400个像素,这些像素仍然保留二维结构。由于采样的位置是随机的,因此采样后的图片无法使用标准的卷积操作。采样后的图片的示例,空洞表示随机移除的像素点。
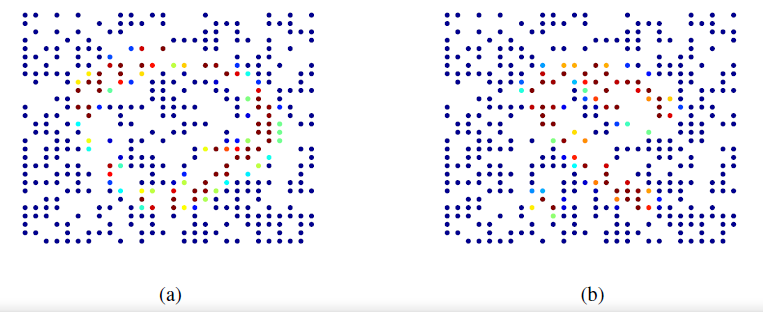
空域层次聚类的可视化,不同的颜色表示不同的簇,颜色种类表示簇的数量。图
a表示b表示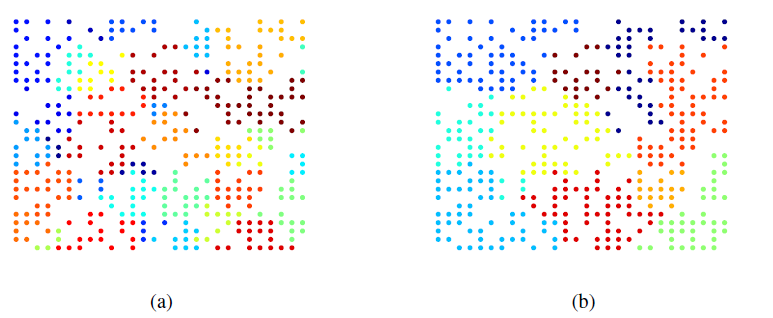
谱域拉普拉斯特征向量的可视化(谱域特征向量每个元素就是对应于每个节点的取值)。图
a表示b表示
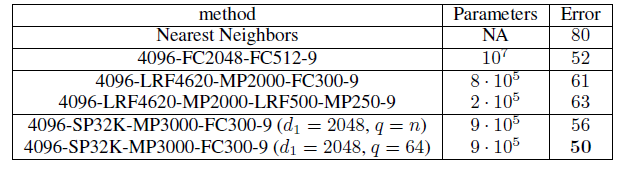
不同模型在
MNIST上分类的结果如下。基准模型为最近邻模型kNN,FCN表示带有N个输出的全连接层,LRFN表示带有N个输出的空域卷积层,MPN表示带有N个输出的最大池化层,SPN是带有N个输出的谱域卷积层。基准模型
kNN(第一行)的分类性能比完整的(没有采样的)MNIST数据集的2.8%分类误差率稍差。两层全连接神经网络(第二行)可以将测试误差降低到
1.8%。两层空域图卷积神经网络(第三行的下面部分)效果最好,这表明空域卷积层核池化层可以有效的将信息汇聚到最终分类器中。
谱域卷积神经网络表现稍差(第四行),但是它的参数数量最少。
采用谱域平滑约束(选择
top的

由于
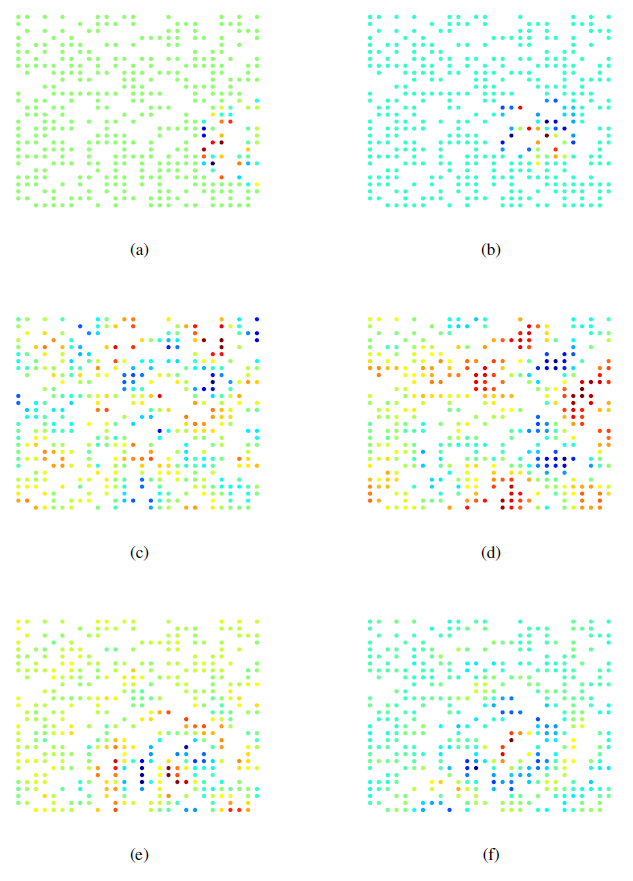
MNIST中的数字由笔画组成,因此具有局部性。空域卷积通过filterfilter上添加平滑约束可以改善分类结果,因为filter被强制具有更好的空间局部性。图
(a),(b)表示同一块感受野在空域卷积的不同层次聚类中的结果。图
(c),(d)表示谱域卷积的两个拉普拉斯特征向量,可以看到结果并没有空间局部性。图
(e),(f)表示采用平滑约束的谱域卷积的两个拉普拉斯特征向量,可以看到结果有一定的空间局部性。
1.4.2 球面 MNIST
我们将
MNIST图片映射到一个球面上,构建方式为:首先从单位球面上随机采样
4096个点然后考虑三维空间的一组正交基
对原始
MNIST数据集的每张图片,我们采样一个随机方差PCA的一组基
由于数字
6和9对于旋转是等价的,所以我们从数据集中移除了所有的9。下面给出了两个球面
MNIST示例: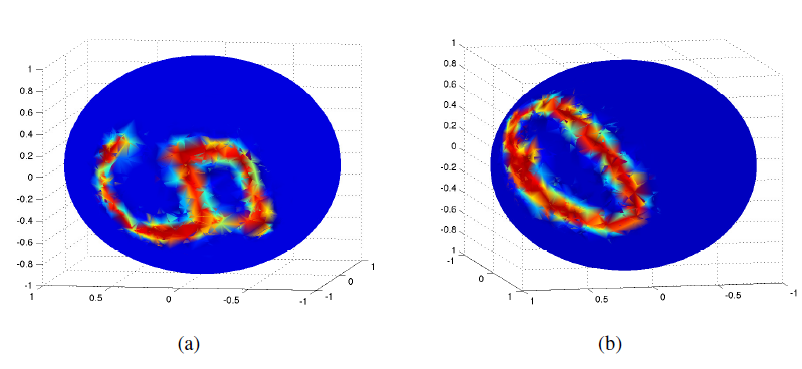
下面给出了谱域构建的图拉普拉斯矩阵的两个特征向量的可视化。图
a表示b表示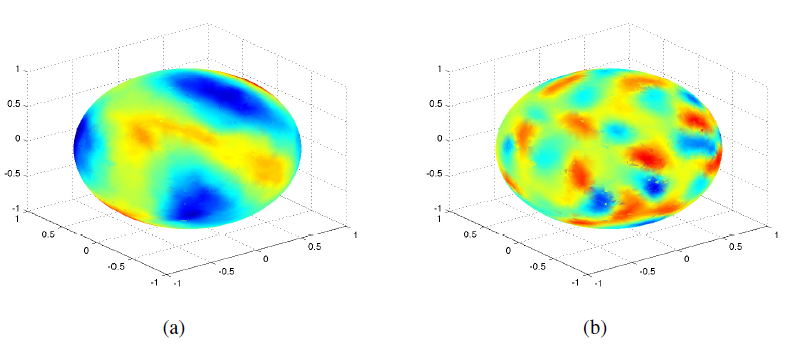
首先考虑“温和”的旋转:
基准的
kNN模型的准确率比上一个实验(随机采样MNIST)差得多。所有神经网络模型都比基准
KNN有着显著改进。空域构建的卷积神经网络、谱域构建的卷积神经网络在比全连接神经网络的参数少得多的情况下,取得了相差无几的性能。

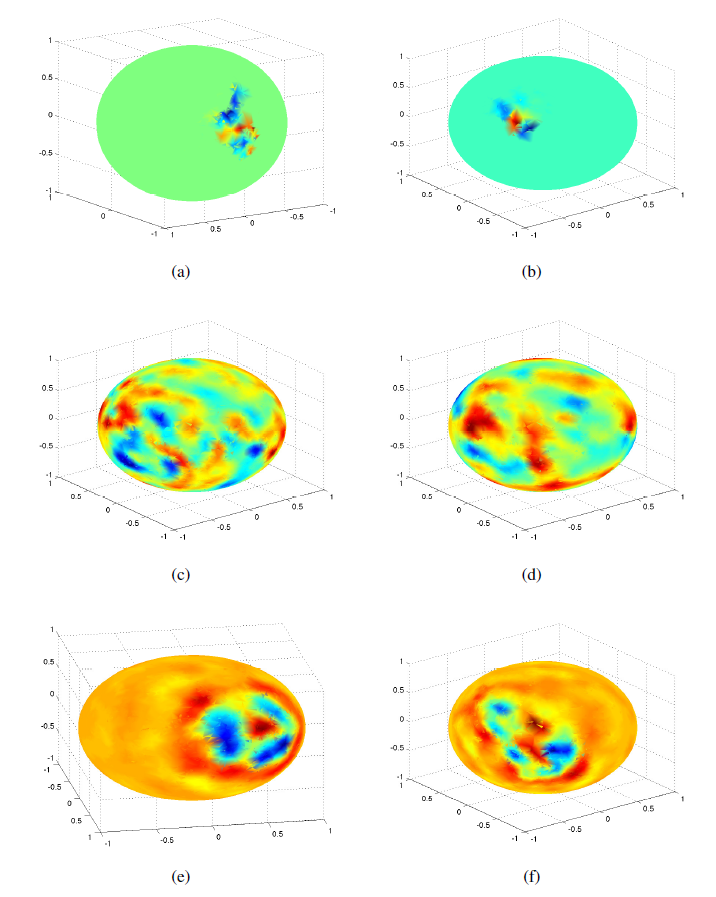
不同卷积神经网络学到的卷积核(即
filter)如下图所示。图
(a),(b)表示同一块感受野在空域卷积的不同层次聚类中的结果。图
(c),(d)表示谱域卷积的两个拉普拉斯特征向量,可以看到结果并没有空间局部性。图
(e),(f)表示采用平滑约束的谱域卷积的两个拉普拉斯特征向量,可以看到结果有一定的空间局部性。
最后我们考虑均匀旋转,此时